Image Editing Examples
















Abstract
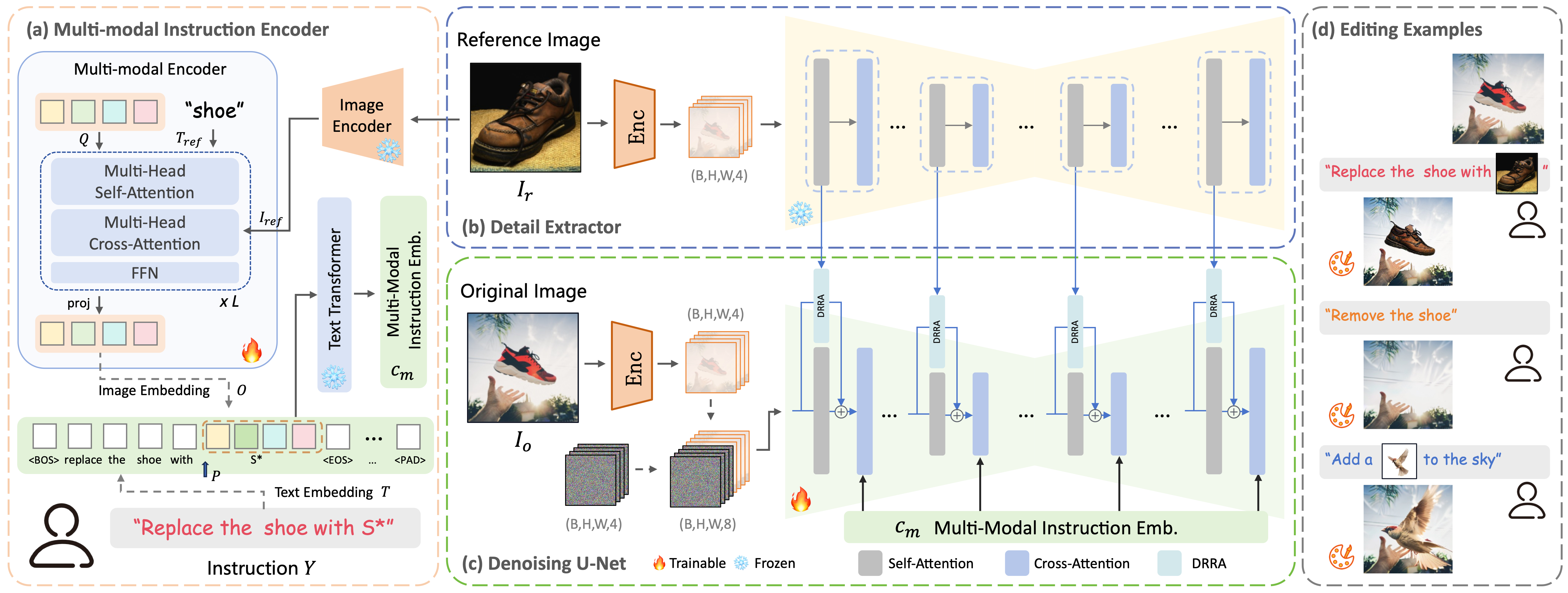
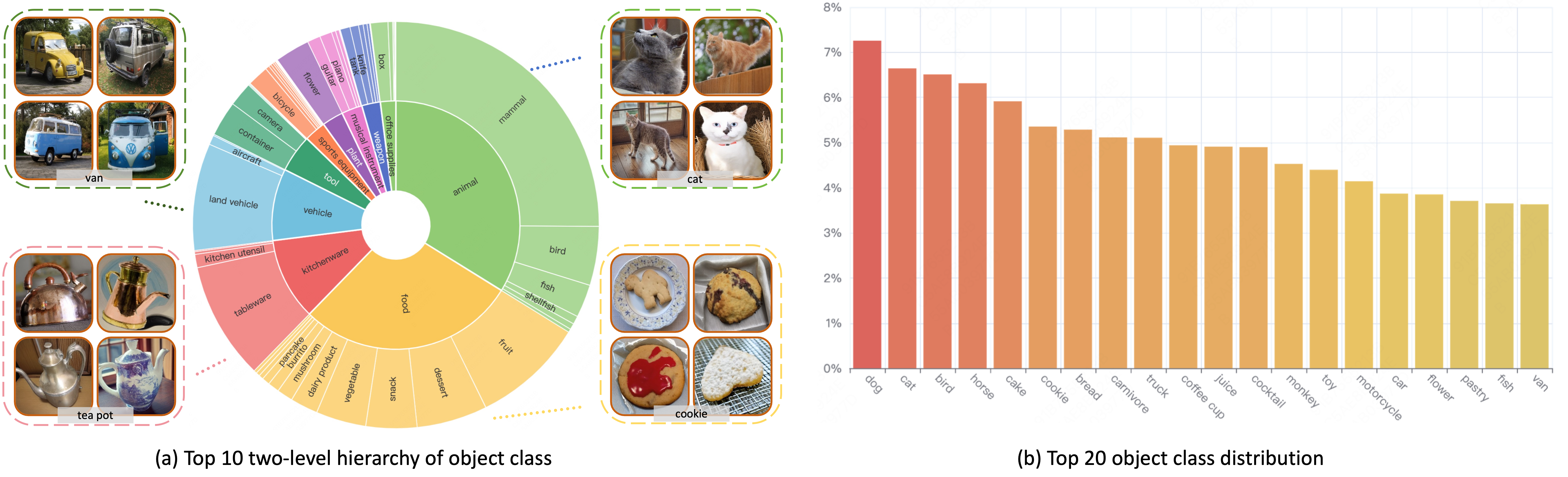
Introducing user-specified visual concepts in image editing is highly practical as these concepts convey the user's intent more precisely than text-based descriptions. We propose FreeEdit, a novel approach for achieving such reference-based image editing, which can accurately reproduce the visual concept from the reference image based on user-friendly language instructions. Our approach leverages the multi-modal instruction encoder to encode language instructions to guide the editing process. This implicit way of locating the editing area eliminates the need for manual editing masks. To enhance the reconstruction of reference details, we introduce the Decoupled Residual ReferAttention (DRRA) module. This module is designed to integrate fine-grained reference features extracted by a detail extractor into the image editing process in a residual way without interfering with the original self-attention. Given that existing datasets are unsuitable for reference-based image editing tasks, particularly due to the difficulty in constructing image triplets that include a reference image, we curate a high-quality dataset, FreeBench, using a newly developed twice-repainting scheme. FreeBench comprises the images before and after editing, detailed editing instructions, as well as a reference image that maintains the identity of the edited object, encompassing tasks such as object addition, replacement, and deletion. By conducting phased training on FreeBench followed by quality tuning, FreeEdit achieves high-quality zero-shot editing through convenient language instructions. We conduct extensive experiments to evaluate the effectiveness of FreeEdit across multiple task types, demonstrating its superiority over existing methods.